TABLE OF CONTENTS
1. 추천 시스템의 종류
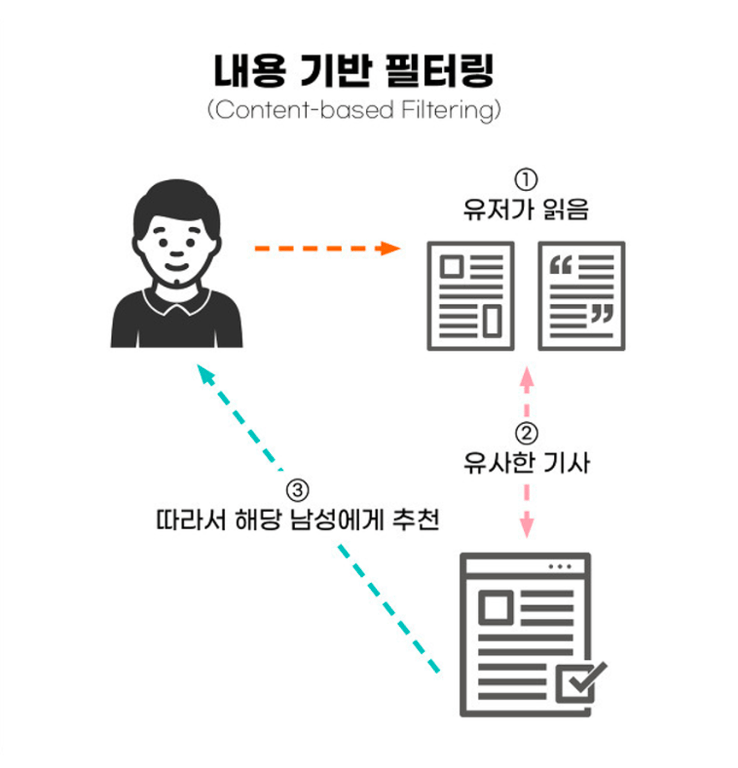
1-1. Content-based Filtering (컨텐츠 기반 추천)
사용자가 좋아한 아이템의 속성(feature) 과 유사한 아이템을 추천
✔️ 특징
- 아이템 특성을 벡터화하여 유사도 기반으로 추천
- “이용자가 좋아한 아이템과 비슷한 아이템” 제공
✔️ 장점
- 다른 사용자 데이터 없이도 추천 가능 (Cold Start에 비교적 강함)
- 추천 근거가 명확 (특성 기반 유사도)
- 신규/비인기 아이템도 추천 가능
✔️ 단점
- 사용자의 기존 관심사가 좁으면 추천 범위도 좁아짐
- 지나치게 유사한 아이템만 추천하는 경향 (Serendipity 떨어짐)
- 아이템 특징을 추출하기 위한 전처리·모델링 비용이 큼
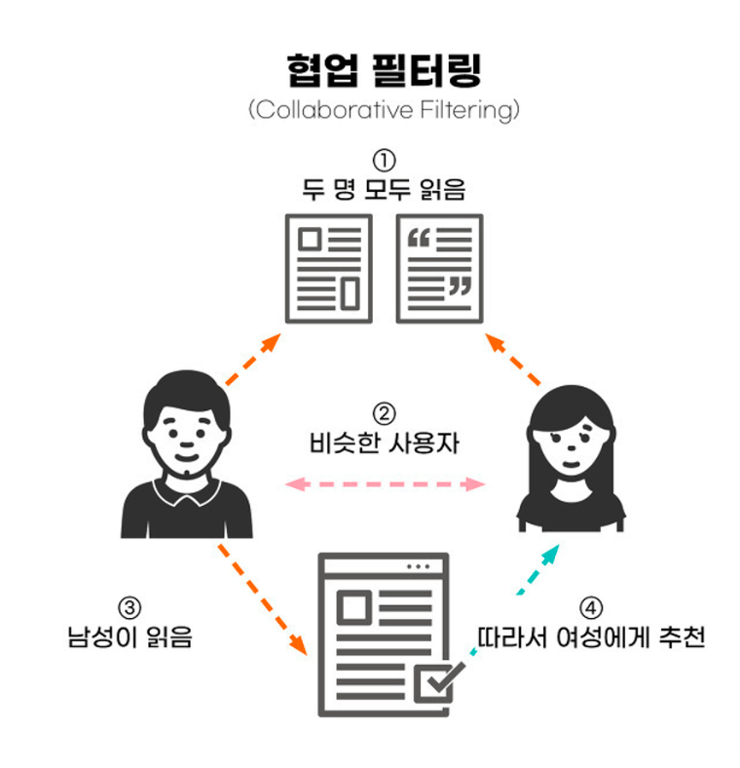
1-2. Collaborative Filtering (협업 필터링)
비슷한 취향의 사용자가 좋아한 아이템을 추천
- 메모리 기반 CF
- 나와 취향이 비슷한 사용자들을 찾고
- 그들이 좋아한 아이템을 추천
- 사용자가 좋아한 아이템과 유사한 패턴을 가진 다른 아이템 추천
- 대규모 서비스에서 안정적(아마존이 이 방식 사용)
✔️ 사용자 기반(User-based)
✔️ 아이템 기반(Item-based)
- 모델 기반 CF
- 사용자와 아이템을 잠재 차원(latent space)에 매핑
- 차원 간 관계는 불명확하지만 유사도 계산에 매우 효과적
- 대표 모델: Matrix Factorization, SVD, ALS
- Classification → 사용자를 클러스터로 분류 후 군집별 추천
- Regression → 평점 예측값을 기반으로 추천
✔️ Latent Factor Model (잠재 요인 모델)
✔️ Classification / Regression
1-3. Hybrid Recommender System
여러 추천 방식을 조합하여 단점을 보완하는 방식
예) Content-based + CF
✔️ 장점
- Cold Start 완화
- 성능 안정적
- 한 알고리즘의 약점을 다른 것이 보완
✔️ 단점
- 시스템 복잡도 증가
- 모델 개발·학습 비용 상승
2. 추천 시스템에 사용되는 데이터 종류
2-1. Explicit Data (명시적 데이터)
✔️ 정의
- 사용자가 의도를 명확히 표현한 데이터
예) 평점, 좋아요/싫어요, 리뷰, 구독
✔️ 장점
- 취향이 정확하게 반영
✔️ 단점
- 사용자 참여율이 낮아 데이터 수집이 어려움
2-2. Implicit Data (암묵적 데이터)
✔️ 정의
- 행동 기반으로 추정한 선호 데이터
예) 클릭, 구매, 검색 기록, 체류 시간
✔️ 장점
- 대규모 데이터 수집 용이
✔️ 단점
- “좋아서 클릭한 것인지/아닌지” 해석이 모호 → 노이즈 존재
3. 추천 시스템에서 사용하는 유사도 측정 방법
아이템/사용자를 벡터화한 뒤 유사도(또는 거리)를 계산해 추천
3-1. 집합 기반
✔️ 자카드 유사도 : 집합 간의 교집합 크기를 이용해서 유사도 측정
✔️ 특징
- 0 이상 1 이하까지 값의 범위가 존재.
- 합집합과 교집합의 크기가 비슷할수록 1의 값을 가짐.
(두 집합 사이의 교집합 크기가 클수록 아이템 간의 유사도가 높음.)
3-2. 각도 기반
✔️ 코사인 유사도 : 벡터 사이의 각도를 측정한 거리를 이용해서 유사도 측정
✔️ 특징
- 0 이상 1 이하까지 값의 범위가 존재.
- 두 벡터의 이루는 각도가 작을수록 유사도는 커짐.
(문헌의 크기와 상관없이 특정 단어가 등장한 비율 만을 유사도 계산에 반영함.)
- 1이면 완전 일치, 0이면 완전 불일치.
3-3. 거리 기반
✔️ 유클리디안 거리 : 벡터 사이의 거리를 이용해서 유사도 측정
✔️ 특징
- 0 이상 1 이하까지 값의 범위가 존재.
- 두 벡터의 이루는 각도는 무시되고 거리만 반영.
- 0이면 완전 일치, 1이면 완전 불일치.
3-4. 상관관계 기반
✔️ 피어슨 상관계수 : 서로 간의 상관관계를 이용해서 유사도 측정
✔️ 특징
- -1 이상 1 이하까지 값의 범위가 존재.
- 점수 기준이 극단적일 경우, 유사도에 영향을 크게 주는 것을 방지하기 위해 사용.
- 1이면 완전 일치, -1이면 완전 불일치.
4. 추천 시스템의 한계점 & 원인
4-1. Cold Start 문제
✔️ 정의 : 추천 시스템이 새롭게 들어온 유저나, 특정 컨셉을 가진 유저에 대한 정보가 충분하지 않아 적절한 상품을 추천해주지 못하는 문제
✔️ 원인
- 신규 유저 → 행동 데이터 부족
- 신규 아이템 → 평가 데이터 부족
- 전체 데이터 부족 → 서비스 초기, 소규모 서비스에서 빈번
- 협업 필터링은 Cold Start에 특히 취약
✔️ 콘텐트 기반의 상대적 강점
- 아이템 특성만 있어도 추천 가능해 Cold Start에 비교적 강함
4-2. 계산 효율성 저하 문제
✔️ 정의 : 사용하는 추천 시스템의 종류에 따라 계산효율성 문제가 발생
✔️ 원인
- CF는 유사도 계산량이 많음
- 사용자가 증가할수록 계산 비용 비례 증가
- 정확도 vs 계산 시간의 trade-off 존재
- 특히 User-based CF는 스케일링 어려움
4-2. Long Tail 문제
✔️ 정의 : 사용자들이 소수의 인기 있는 항목에만 관심을 보이고, 관심이 저조한 아이템은 정보가 부족하여 추천되지 못하기 때문에 다양성이 떨어지는 문제
✔️ 원인
- 인기 콘텐츠에만 많은 클릭·평점이 집중
- 비주류 콘텐츠는 데이터 부족으로 추천에서 제외
- 다양성(Diversity) 저하
5. 해결 방안
5-1. 데이터 확보
- 프로필 입력 유도
- 온보딩 퀘스천 생성
- 사용자의 행동을 세밀하게 수집
5-2. 하이브리드 방식 적용
- 콘텐츠 기반 + 협업 필터링
- 모델 기반 + 규칙 기반 혼합
→ Cold Start & 롱테일 문제 완화
5-3. 다양성 강화 기법
- 탐색(Exploration) 가중치 적용
- long-tail 아이템 노출 비율을 높이는 알고리즘
- 강화학습 기반 추천(탐험-활용 균형)
 Made with Bullet
Made with Bullet