Q1. 축약형(2단계) 단계 예측의 잔차는?
2단계의 .resid에서 얻는 잔차와 동일하지 않음을 조심할 것!
축약형 단계 예측의 잔차를 이용하여 도구변수 추정값에 대한 표준오차를 계산할 수 있다. 
앞선 코드와 동일한 표준오차
코드 예시 및 결과
Z= df["prime_eligible"] T= df["prime_card"] n = len(df) e_iv = df["pv"] - iv_regr.predict(df) compliance = np. cov(T, Z)[0, 1]/Z.var() se = np.std(e_iv)/(compliance*np.std(Z)*np.sqrt(n)) print("SE IV:", se) print ("95% CI:", [late - 2*se, late +2*se])
# 결과 SE IV: 80.52861026141942 95% C:I [596.6401590115549, 918.7546000572327]
추가로, linearmodels에서 2SLS 모듈을 사용하면, 결과 재확인이 가능하다.
코드 예시 및 결과
from linearmodels import IV2SLS formula ='pv ~1+[prime_card ~prime_eligible]' iv_model = IV2SLS. from_formula(formula, df).fit(cov_type="unadjusted") iv_model.summary.tables[1]
Q2. 표준오차 공식이 불응 실험에서 마주하는 어려움을 일정 부분 설명해줄 수 있는 이유?
- 이항분포 표준편차의 최댓값 = 0.5
이항분포 표준편차의 최댓값이 0.5인 이유?
표준편차 가 최대가 되려면 가 최대가 되어야 한다.
이항 변수의 경우, 는 = 0.5일 때 최대값을 가진다.
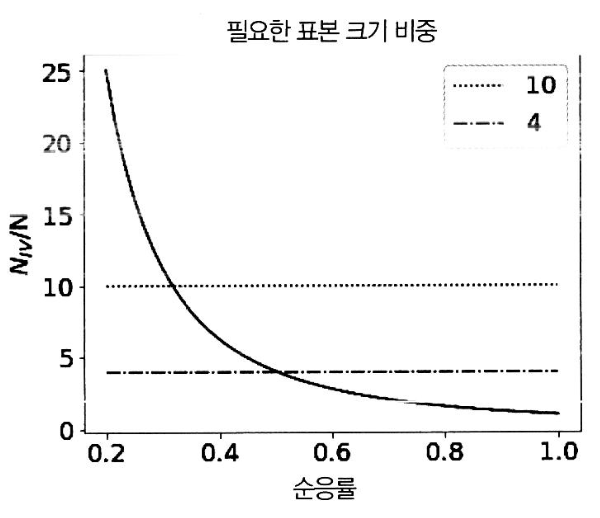
- 순응률 항 추가
- 순응률이 100%인 경우, Z = T, b = 1
- 불응인 경우, b < 1이 되면서 분모의 값이 작아지므로 표준오차 증가
→ 따라서, 순응률이 50%라면 표준오차는 OLS 때보다 2배 증가하고, 이에 따라 필요한 표본 수도 늘어남.
11.8 통제변수와 도구변수 추가
Q1. 프라임 신용카드 데이터
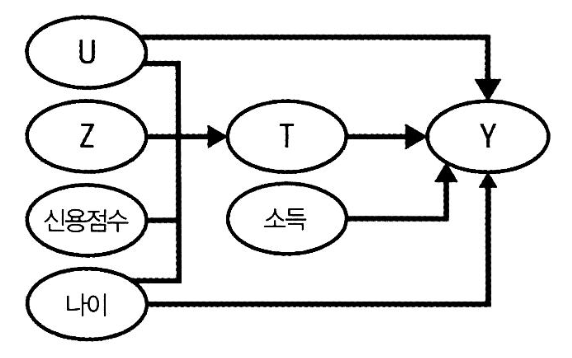
- 프라임 신용카드 데이터
- 기본 변수 :
처치변수(T)도구변수(Z)결과변수(Y) - 처치변수(T) : 실험이나 연구에서 어떤 처치를 받았는지, 인과관계에서 원인 역할을 하는 변수
- 도구변수(Z) : 실험이나 연구에서 처치변수와 결과변수 간의 인과관계를 추정하기 위해 사용하는 변수
- 결과변수(Y) : 실험이나 연구에서 처치에 대한 어떤 결과를 얻었는지, 결과 역할을 하는 변수
- 추가 변수(공변량) :
소득나이신용점수
위 변수들의 개념과 특징이 헷갈린다면!
- 인과관계 해석
ㅤ | 결과(Y) 예측력 | 순응(T) 여부 예측력 | 비고 |
소득 | O | X | ㅤ |
신용점수 | X | O | ㅤ |
나이 | O | O | 교란 요인 |
→ 이러한 변수를 잘 사용한다면, 표준오차 줄일 수 있음!
- 변수 활용 예시 및 유의사항
- 예시
- 신용점수는 순응(T)의 원인이지만 결과(Y)의 원인은 아니므로, 추가적인 도구변수로 사용 가능.
- 유의사항
- 신용점수를 2SLS 모델의 두 번째 단계*에도 추가하면, 오차가 증가할 수 있음.
- 따라서, 결과에 잘 영향을 주는 통제 변수(예: 소득)를 포함하면, 도구 변수 추정값의 분산을 줄일 수 있음.
→ 도구변수를 추가하면, LATE(지역 평균 처리 효과)의 표준오차를 줄일 수 있음.
두 번째 단계란?
첫 번째 단계에서 추정한 처치변수를 사용하여 결과변수를 예측하는 과정
그럼, 첫 번째 단계는?
도구변수를 사용하여 처치변수를 예측하는 과정 (도구변수가 처치변수에만 영향을 미치고, 결과변수에는 영향을 미치지 않는 것이 중요)
→ 공변량이 순응(T)과 결과(Y) 모두에 영향을 주기 때문.
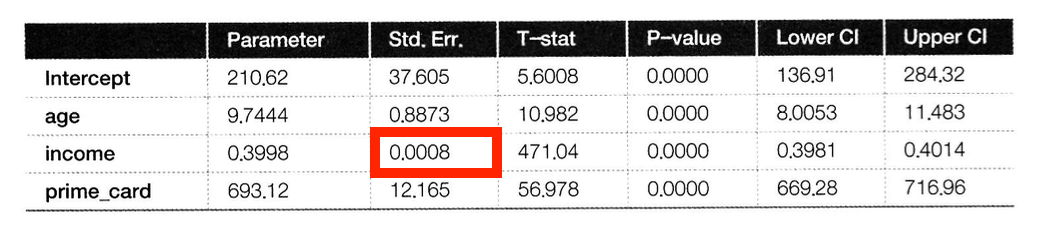
Q2. 2SLS 직접 구현
1단계 : 처치(T)를 도구변수(Z)와 추가 공변량(X)에 회귀
- 모델 설정 :
T ~ Z + X
- 예시 :
prime_card ~ prime_eligible + credit_score + income + age
- 코드 구현 :
formula 1st = "prime_card ~ prime_eligible + credit_score + income+age" first_stage =smf.ols(formula_1st, data=df).fit()
2단계 : 결과(Y)를 1단계에서 얻은 처치(T_hat)와 추가 공변량(X)에 회귀
- 모델 설정 :
Y ~ T_hat + X
- 예시 :
pu ~ prime_card + income + age(여기서prime_card는 1단계에서 얻은 적합된 값)
- 코드 예시 :
iv_model = smf.ols( "pu ~prime_card +income +age", data=df.assign(prime_card=first_stage.fittedvalues)).fit()
Q3. 행렬을 사용한 2SLS 구현
2SLS 직접 구현하면 도구변수 추정값은 얻을 수 있지만 표준오차는 달라지기 때문에, 표준오차를 구하고 싶다면 다음과 같은 과정을 따라해야 한다.
도구 변수 행렬(Z)과 처치 행렬(X)에 추가 공변량(X)을 포함
- 1단계 회귀 :
- 회귀 계산 :
- : 도구변수들 간의 상관관계를 나타내는 행렬
- : 위 행렬을 역행렬로 변환하여, 도구변수들 간의 관계를 보정
- : 도구변수와 처치변수 간의 상관관계를 나타내는 행렬
- : 이 모든 요소를 결합하여 계산하면, 도구변수를 통해 추정된 처치변수의 예측값을 얻음
계산식 뜯어보기
- 회귀 계수 추정 :
- 계산 :
- : 예측된 처치변수와 그 자신과의 상관관계를 나타내는 행렬
- : 예측된 처치변수와 결과변수 간의 상관관계를 나타내는 행렬
- : 이 모든 요소를 결합하여 계산하면, 처치변수와 결과변수 간의 인과관계를 추정
계산식 뜯어보기
- 코드 예시 :
Z = df[["prime_eligible", "credit_score", "income", "age"]].values X = df[["prime_card", "income", "age"]].values Y = df[["pv"]].values X_hat = Z.dot(np.linalg.inv(Z.T.dot(Z)).dot(Z.T).dot(X)) b_iv = np.linalg.inv(X_hat.T.dot(X_hat)).dot(X_hat.T).dot(Y)
Q4. 표준오차 계산
앞서 구한 회귀 계수를 바탕으로 표준오차를 계산한다.
- 오차 추정 :
- 코드 예시 :
e_hat_iv = Y - X_.dot(b_iv) var = e_hat_iv.var() * np.diag(np.linalg.inv(X_hat.T.dot(X_hat))) np.sqrt(var[1])
Q5. 표본 늘리는 방법 외에도, 표준오차를 줄이는 방법은?
- 1단계의 증가:
- 순응을 잘 예측하는 강력한 도구 변수를 찾는 것.
- 결과(Y)에 영향을 미치지 않으면서 배제 제약을 만족해야 함.
- T에 대한 예측력이 높은 변수 제거:
- 1단계의 오차(잔차)를 줄여 를 증가시키기.
- 결과(Y)의 예측력이 높은 변수 추가:
- 결과(Y)의 예측력이 높은 변수를 찾아, 2단계 잔차를 줄이는 것.
2SLS 모델의 성능을 높이는 가장 현실적인 방법은 결과(Y)를 잘 예측하는 변수를 찾는 것.
→ 실전에서 도구 변수를 찾는 것은 매우 어렵기 때문.
 Made with Bullet
Made with Bullet