시작 태그 안에서 사용되는 것으로 좀 더 구체화된 명령어 체계 : 속성은 HTML 요소 중에서도 언제나 시작 태그 내에서만 정의되며, 속성 이름과 속성값(value)으로 표현됨.
HTML 구조
<!DOCTYPE html>
문서의 최상단에 HTML5 버전임을 선언합니다.
<html> ... </html>
HTML 문서의 전체 범위를 알려줍니다.
<head> ... </head>
문서의 정보를 나타내는 범위입니다. : 페이지를 조회하는 사람들에게 보여주는 콘텐츠가 아닌 당신이 HTML 페이지에 포함하고 싶어하는 모든 재료들을 위한 컨테이너 역할 - 주변 파일(js,css)을 연결할 때에도 HTML 문서에 관한 '정보'이므로 이 곳에 작성합니다. - 페이지 설명, 콘텐츠를 꾸미기 위한 CSS, 문자 집합 선언 등과 같은 것들을 포함합니다.
<body> ... </body>
문서의 구조를 나타내는 범위입니다. : 페이지에 방문한 모든 웹 사용자들에게 보여주길 원하는 모든 컨텐트를 담고 있는 역할 - 텍스트, 이미지, 비디오, 게임, 플레이할 수 있는 오디오 트랙
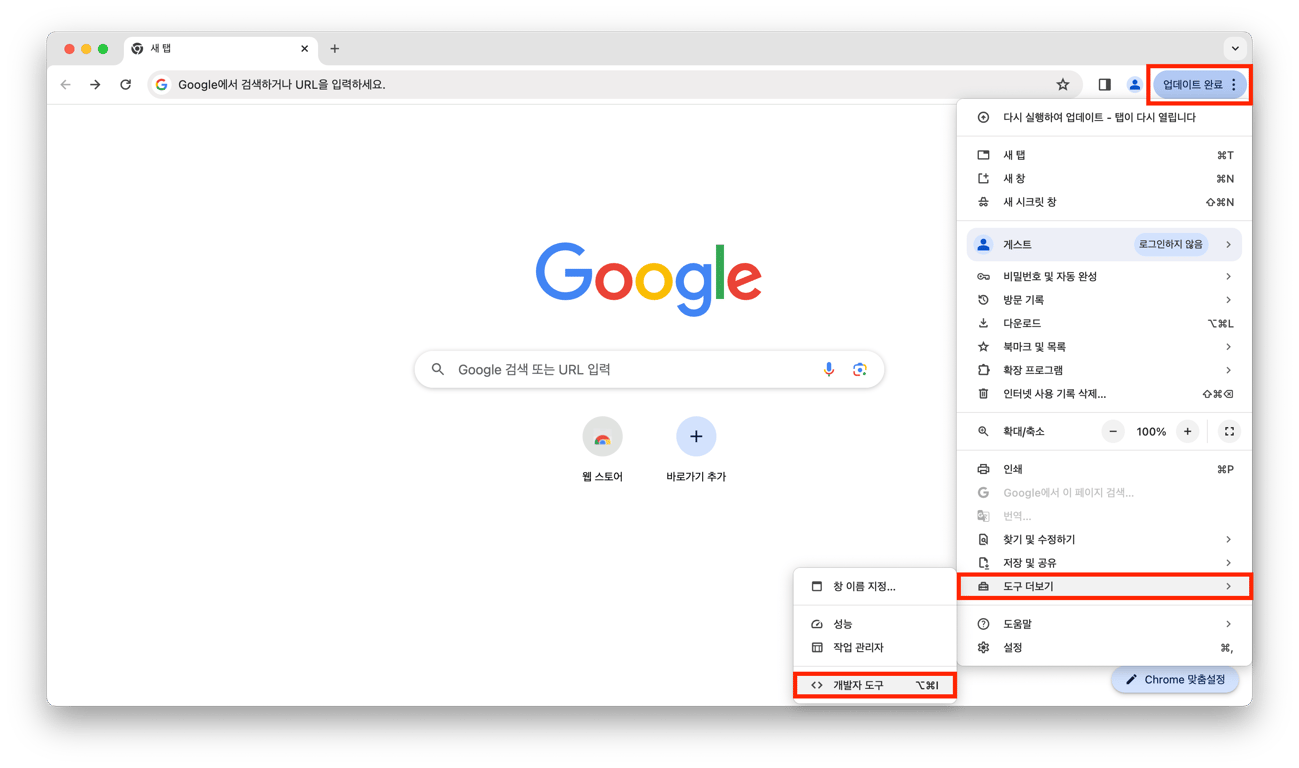
HTML 구조 확인하는 방법
방법 1) [설정] → [도구 더보기] → [개발자 도구]
방법 2) [F12]
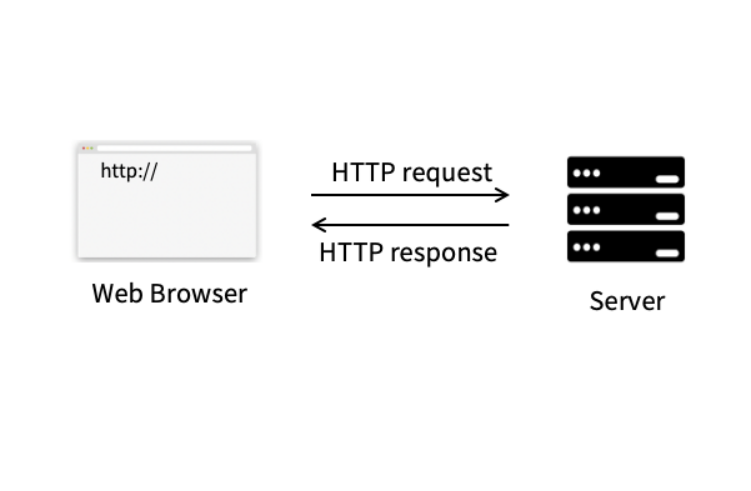
정적 수집, 동적 수집의 정의
정적 수집이란?
⭐
멈춰있는 페이지의 HTML을 requests 혹은 urllib 패키지를 이용해 가져와서 beautifulsoup 패키지로 파싱(*)하여 원하는 정보를 수집
❓ 파싱이란?
복잡한 HTML 문서를 잘 분류, 정리하여 다루기 쉽게 바꾸는 작업
동적 수집이란?
⭐
계속 움직이는 페이지를 다루기 위해 selenium 패키지로 chromdriver를 제어
→ 특정 url로 접속해서 로그인 하거나 버튼을 클릭하는 식으로 원하는 정보가 있는 페이지 까지 도달
→ 태그는 이름, 속성, 값으로 구성되어있기 때문에, find로 해당 이름이나 속성, 값을 특정하여 태그를 찾을 수 있다.
.find()
매칭되는 첫 번째 태그 하나만 찾는 것
.find_all()
매칭되는 태그 모두 다 찾는 것
.find() 예시
tag = <p class = 'example' id = 'test'> BOAZ 최고 </p>
soup = BeautifulSoup(tag)
# 태그 이름만 특정
soup.find('p')
# 태그 속성만 특정
soup.find(class_ = 'example')
soup.find(attrs = {'class' : 'example'})
# 태그 이름과 속성 모두 특정
soup.find('p', class_ = 'example')
.find_all() 예시
여러 개의 p 태그가 존재하고, 두 번째 “22기 최고”의 텍스트만 가져오고 싶을 때!
tag = <p class = 'example' id = 'test'> BOAZ 최고 </p>
<p class = 'example' id = 'test'> 22기 최고 </p>
soup = BeautifulSoup(tag)
# 태그 속성만 특정
soup.find_all(attrs = {'class' : 'example'})[1]
코드 모음집
STEP_1. 필요한 모듈 import
# HTTP 요청을 보내고 응답을 받는 기능을 사용하기 위한 import
import requests
# 웹 페이지에서 필요한 정보를 쉽게 가져오기 위한 import
from bs4 import BeautifulSoup as bs
# 데이터를 구조화하고 처리하는 데 사용하기 위한 import
import pandas as pd
STEP_2. 원하는 url로 접속
# url 주소
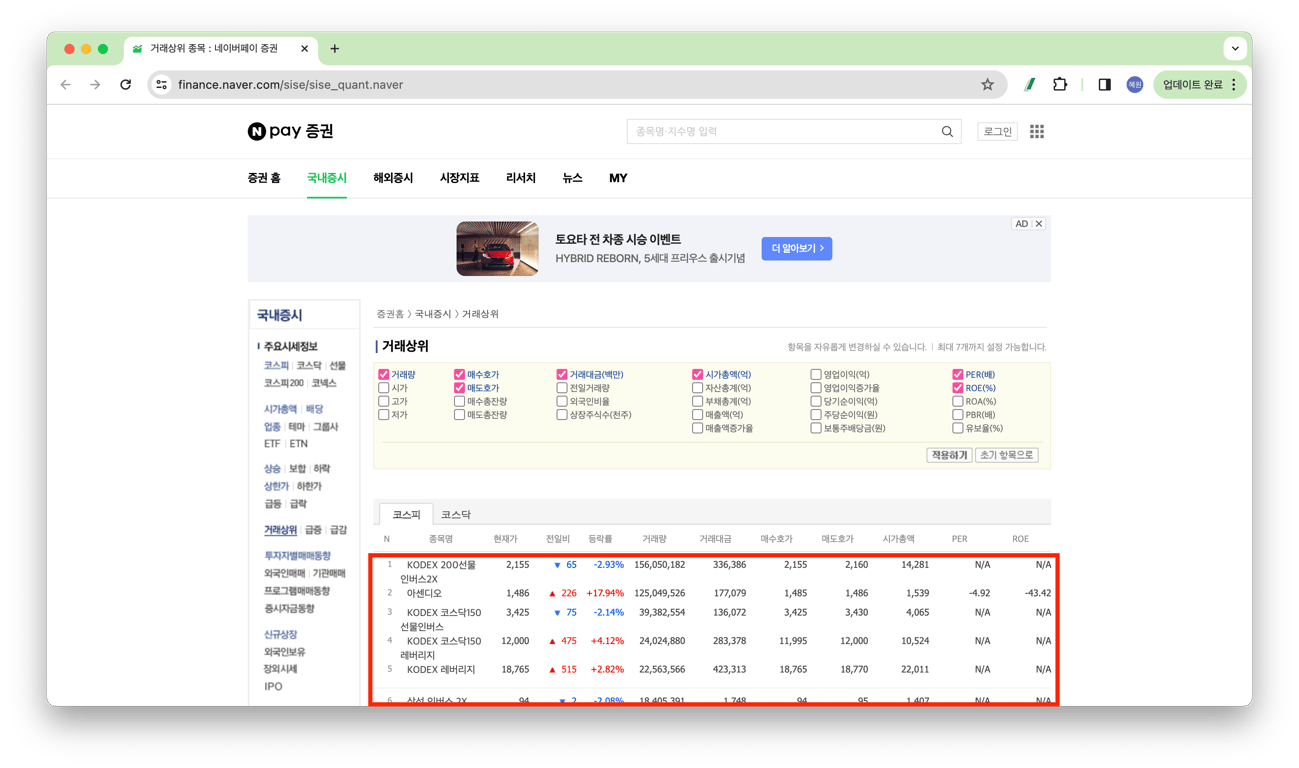
url = 'https://finance.naver.com/sise/sise_quant.naver'
# 해당 URL에 HTTP 요청을 보내고, 변수 response에 응답을 저장
response = requests.get(url)
STEP_3. 웹페이지에서 가져온 HTML 문서 파싱
# response 객체의 내용을 HTML 파싱하여 soup 객체로 만든 후 출력
soup = bs(response.content, 'html.parser')
print(soup)
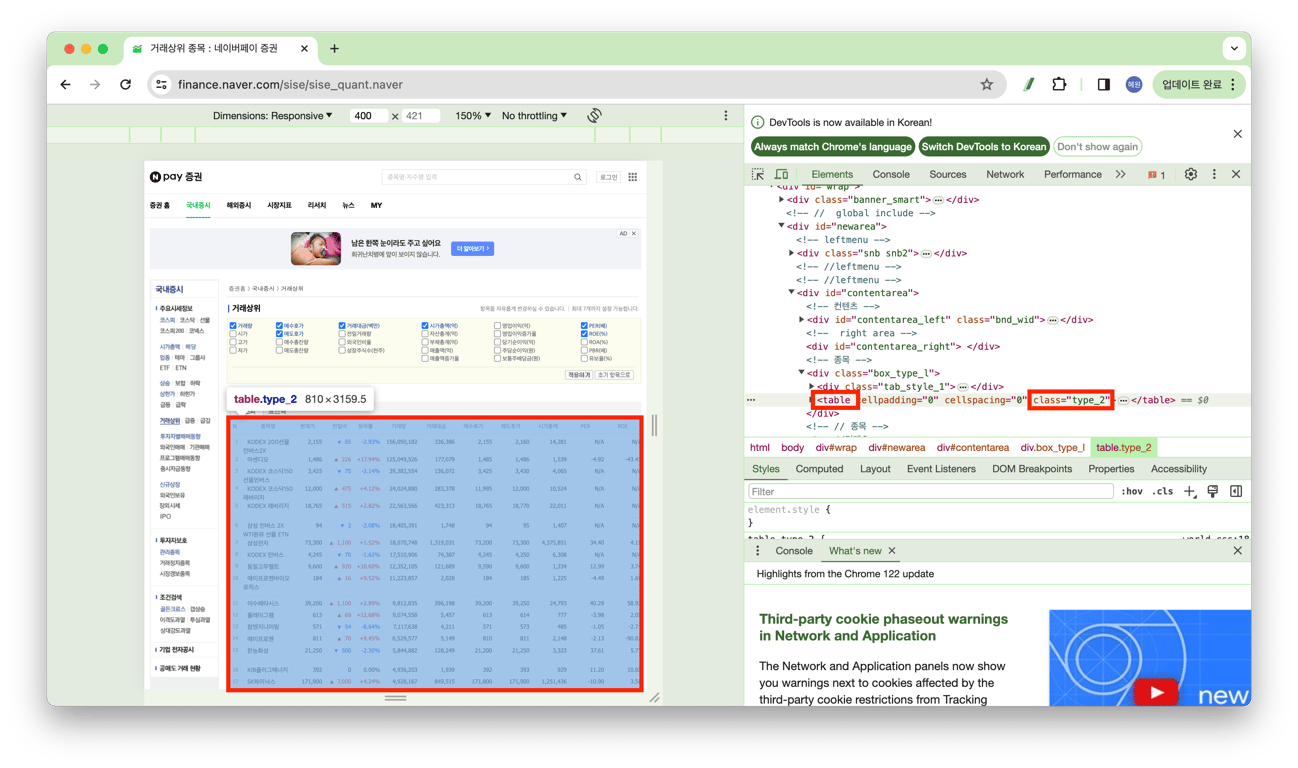
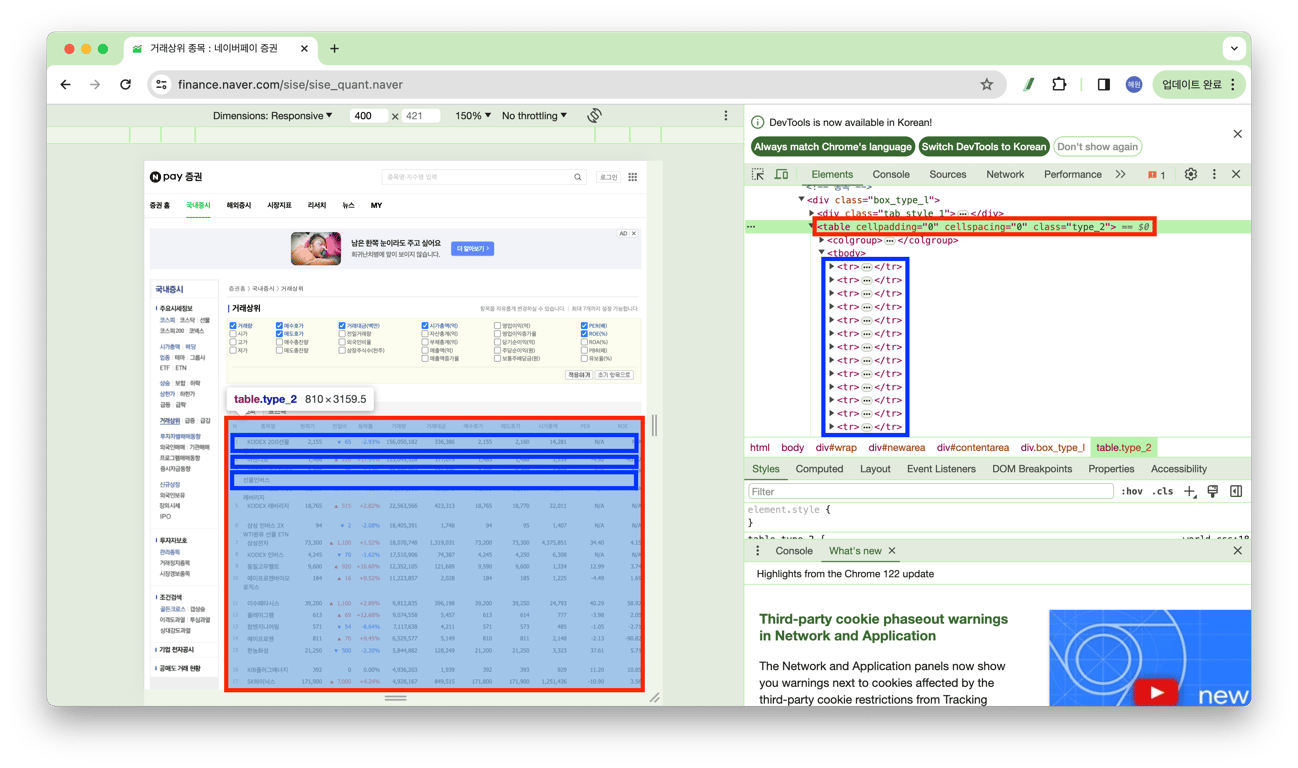
STEP_4. 크롤링할 표 찾기
# <table> 태그 중에서 클래스가 'type_2'인 것을 찾아서 table 변수에 저장
table = soup.find('table', class_ = 'type_2')
print(table)
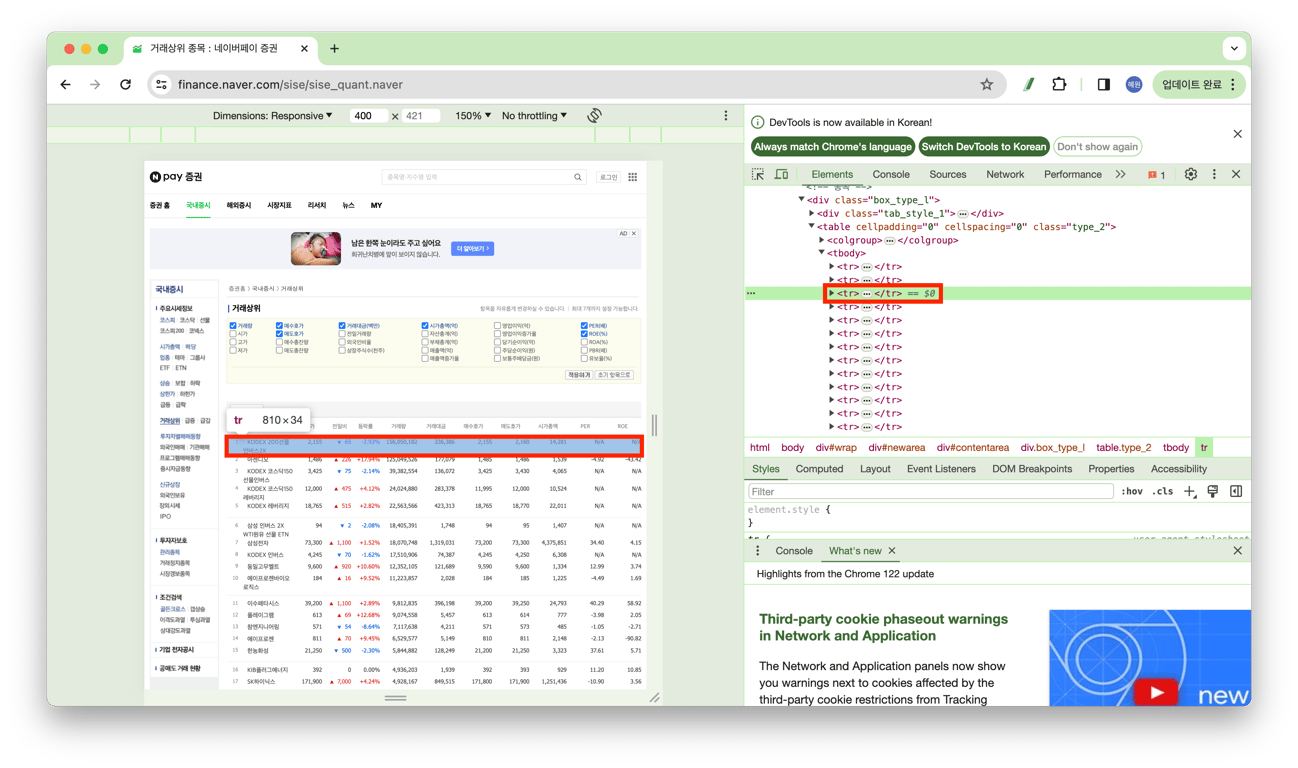
# 젤 첫 행이 tr의 세 번째에 위치해서 해당 코드 돌리면 젤 첫 행이 나옴.
td1 = tr[2].find_all('td')
print(td1)
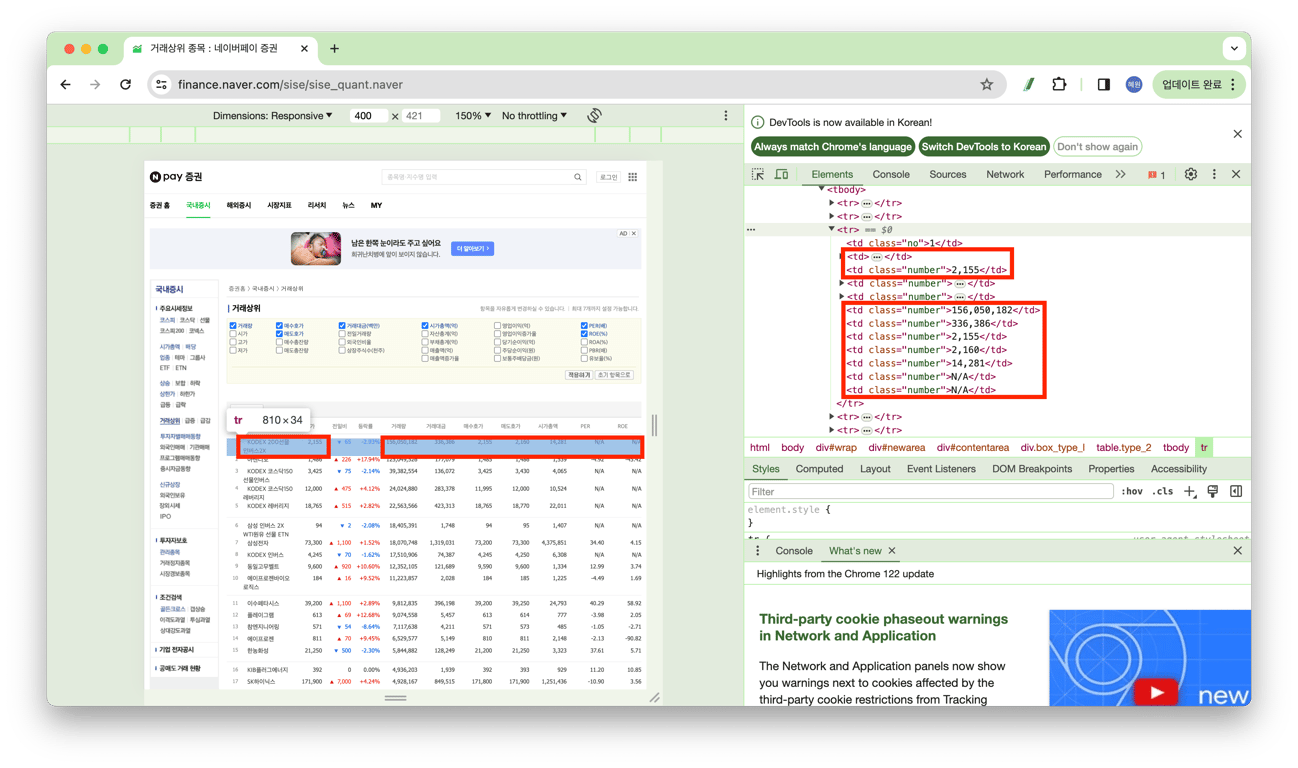
STEP_7. 표의 첫 번째 행의 값만 찾기
# 종목명, 현재가, 거래량, 거래대금, 매수호가, 매도호가, 시가총액, PER, ROE 정보 가져오기
variables = []
for index in range(1, 12):
if index in [1, 2, 5, 6, 7, 8, 9, 10, 11]:
variables.append(td1[index].text)
for variable in variables:
print(variable)
STEP_8. 표의 모든 행의 값만 찾기
# 행별로 종목명, 현재가, 거래량, 거래대금, 매수호가, 매도호가, 시가총액, PER, ROE 정보 가져오기
data = [] # 모든 데이터를 담을 리스트
for tr in table.find_all('tr'): # 모든 <tr> 태그를 찾아서 반복 (각 행의 데이터를 가져옴)
tds = list(tr.find_all('td')) # 모든 <td> 태그를 찾아서 리스트로 만듦 (각 행의 값을 리스트로 만듦)
row_data = [] # 한 행의 데이터를 담을 리스트
for td in tds: # <td> 태그 리스트 반복 (각 행의 값을 가져옴)
if td.find('a'): # <td> 안에 <a> 태그가 있으면 (지점인지 확인)
row_variables = [] # 한 행의 값들에 대한 데이터를 담을 리스트
for index in range(1, 12):
if index in [1, 2, 5, 6, 7, 8, 9, 10, 11]:
row_variables.append(tds[index].text)
row_data.extend(row_variables) # 현재 행의 데이터를 전체 데이터 리스트에 추가
if row_data: # 행 데이터가 비어있지 않으면 추가
data.append(row_data)
# 결과 출력
for row in data:
print(row)
.find_element / .find_elements 함수 : 하나의 / 여러 개의 웹 요소 찾는 함수
find_element(By.ID, ‘***’)
ID 속성을 사용하여 웹 요소를 찾습니다.
find_element(By.NAME, ‘***’)
NAME 속성을 사용하여 웹 요소를 찾습니다.
find_element(By.CLASS_NAME, ‘***’)
CLASS_NAME 속성을 사용하여 웹 요소를 찾습니다.
find_element(By.TAG_NAME, ‘***’)
TAG_NAME 속성을 사용하여 웹 요소를 찾습니다.
find_element(By.CSS_SELECTOR, ‘***’)
CSS_SELECTOR 속성을 사용하여 웹 요소를 찾습니다.
find_element(By.XPATH, ‘***’)
XPATH 속성을 사용하여 웹 요소를 찾습니다.
코드 모음집
STEP_1. 필요한 모듈 import
# selenium의 webdriver를 사용하기 위한 import
from selenium import webdriver
# selenium으로 키를 조작하기 위한 import
from selenium.webdriver.common.keys import Keys
# selenium으로 매개변수 경로를 이용하기 위한 import
from selenium.webdriver.common.by import By
# 페이지 로딩을 기다리는데에 사용할 time 모듈 import
import time
# 데이터를 구조화하고 처리하는 데 사용하기 위한 import
import pandas as pd
STEP_2. 크롬드라이버로 원하는 url로 접속
# 크롬드라이버 실행
driver = webdriver.Chrome()
#크롬 드라이버에 url 주소 넣고 실행
url = 'https://www.naver.com/'
driver.get(url)
# 페이지가 완전히 로딩되도록 3초동안 기다림
time.sleep(3)
STEP_3. 검색할 키워드 입력
# 검색할 키워드 입력
query = input('검색할 키워드를 입력하세요: ')
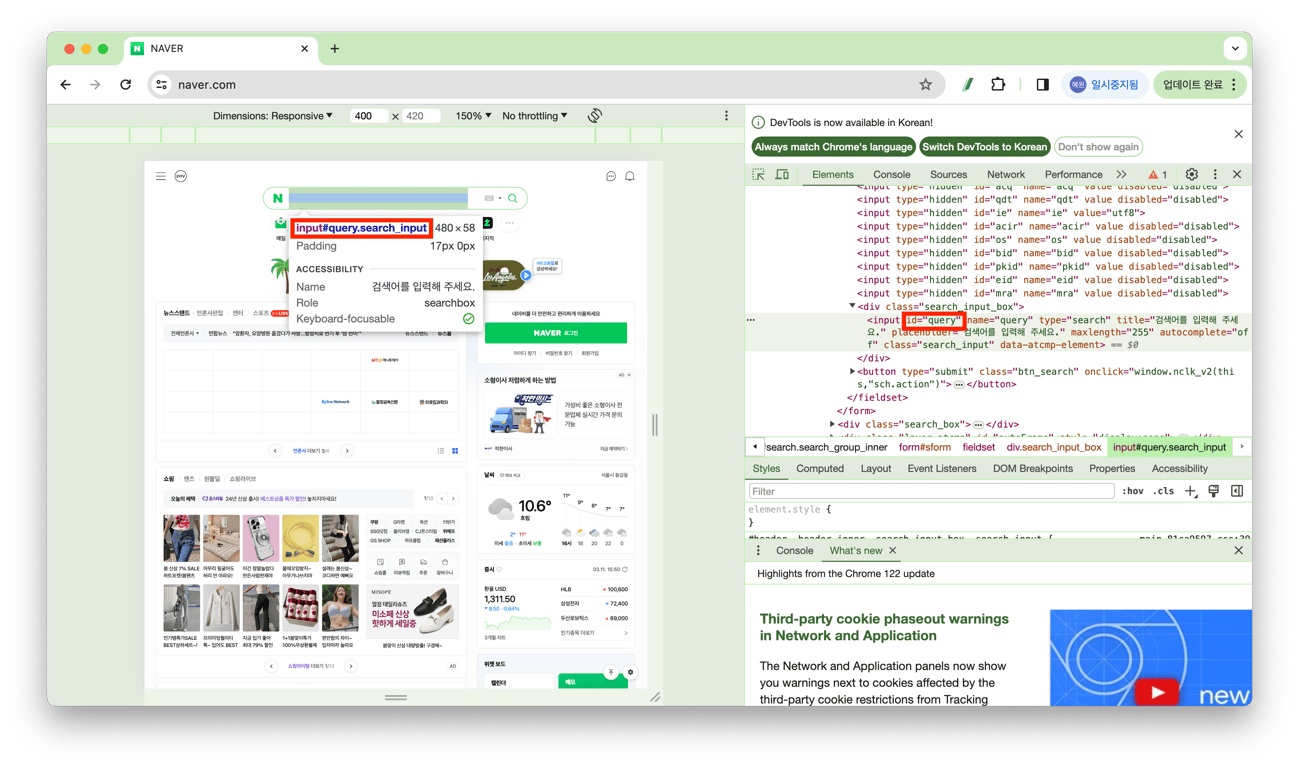
# 검색어 창을 찾아 search 변수에 저장 (ID 이용방식)
search_box = driver.find_element(By.ID, 'query')
# 검색창에 검색어를 입력한 상태가 되도록 하기
search_box.send_keys(query)
# 검색어를 치고 엔터키를 입력하는 것과 같은 효과
search_box.send_keys(Keys.RETURN)
# 페이지가 완전히 로딩되도록 2초동안 기다림
time.sleep(2)
STEP_4. 뉴스 탭 클릭 및 페이지 스크롤
# 뉴스 탭 클릭하기
driver.find_element(By.XPATH,'//*[@id="lnb"]/div[1]/div/div[1]/div/div[1]/div[9]').click()
# 페이지가 완전히 로딩되도록 2초동안 기다림
time.sleep(2)
# 스크롤을 최하단으로 내리기 위한 함수
def scroll_to_bottom(driver):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
# 초기에 한 번 스크롤
scroll_to_bottom(driver)
# 일정 횟수만큼 스크롤을 반복하기 : 스크롤 할 때마다 새로운 기사가 추가되므로
scroll_count = 10
for _ in range(scroll_count):
scroll_to_bottom(driver)
# 스크롤을 모두 내린 후의 페이지 소스 가져오기
page_source = driver.page_source
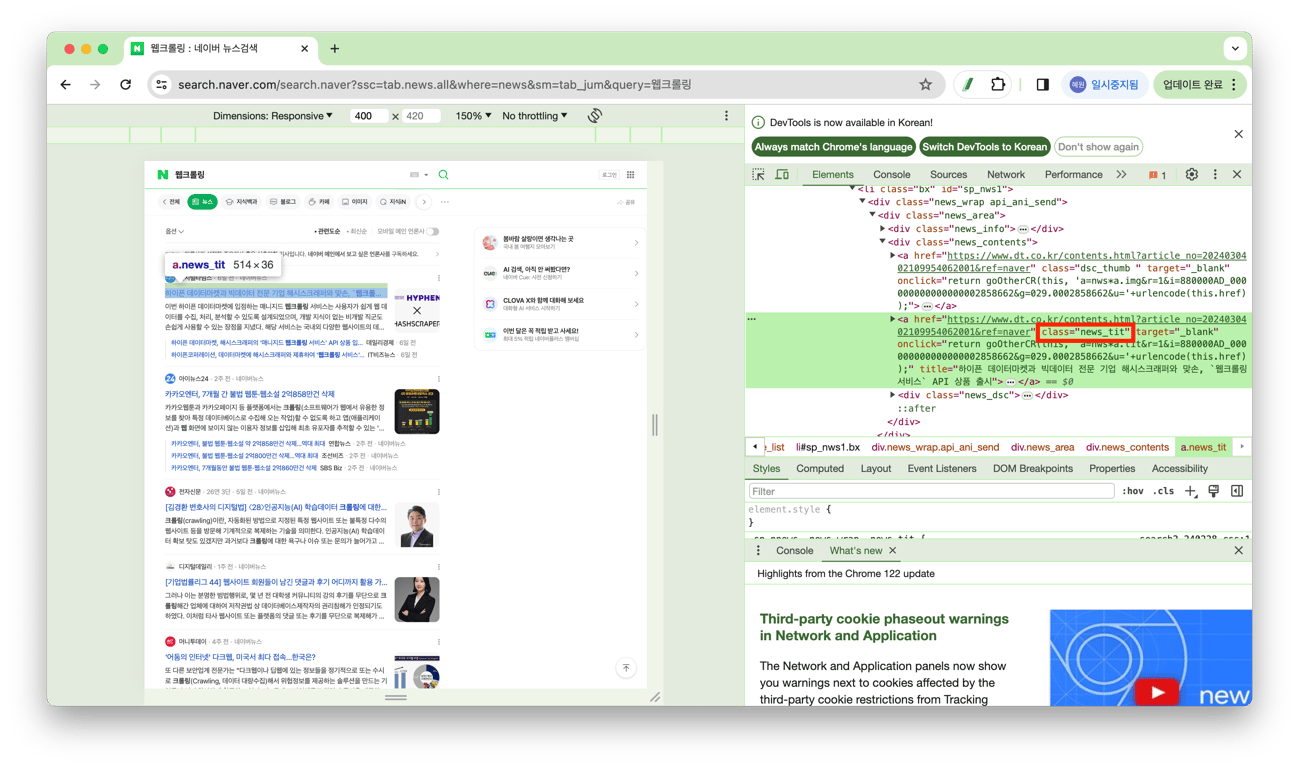
STEP_5. 뉴스 제목 텍스트 추출
#여러 개의 요소를 가져오기 때문에 find_elemesnts
news_titles = driver.find_elements(By.CLASS_NAME, 'news_tit')
for i in news_titles:
title = i.text # 뉴스 기사 제목 가져오기
print(title)
STEP_6. 뉴스 하이퍼링크 추출
for i in news_titles:
href = i.get_attribute('href') # get_attribute = 속성값 가져오기
print(href)
STEP_7. 뉴스 제목 및 하이퍼링크 함께 추출
titlelist = [] # 뉴스 기사 제목 리스트 생성
hreflist = [] # 뉴스 기사 링크 리스트 생성
for i in news_titles:
title = i.text # 뉴스 기사 제목(텍스트)가져오기
titlelist.append(title)
href = i.get_attribute('href') # 뉴스 링크 가져오기(속성값 = href)
hreflist.append(href)
print(titlelist)
print(hreflist)
STEP_8. 데이터프레임으로 변환하여 csv 파일로 저장
df = pd.DataFrame({"title": titlelist, "href":hreflist})
df
df.to_csv('/Users/hyewon/Downloads/24-1 동적 크롤링.csv')








![[알고리즘] 그래프 이론(Graph Theory) 알고리즘](https://assets.bullet.site/files?id=32d13e36-0d89-80fa-aeb5-cc443b043036&url=attachment:43c8b1cf-9c32-4cb0-9eb7-ecd02d7f806a:image.png)
![[SQL] Programmers_SELECT. 특정 세대의 대장균 찾기](https://assets.bullet.site/files?id=32c13e36-0d89-81c0-9ab0-c1bc666eeac9&url=attachment:4075d448-f1c5-41fb-b852-772b5de179a4:image.png)
![[서평] 다크 데이터](https://assets.bullet.site/files?id=32c13e36-0d89-8121-93ba-cef7e10d8888&url=attachment:6920c9f4-6a6d-4d1a-afef-44e14a26f80d:image.png)
 Made with Bullet
Made with Bullet